
AI와 데이터 사이언스의 이론과 실전
데이터 로더 및 간단한 CNN만들기 실습 본문
1. 데이터 로더(Data Loader)
데이터의 양이 많을때 배치단위로 학습하는 방법
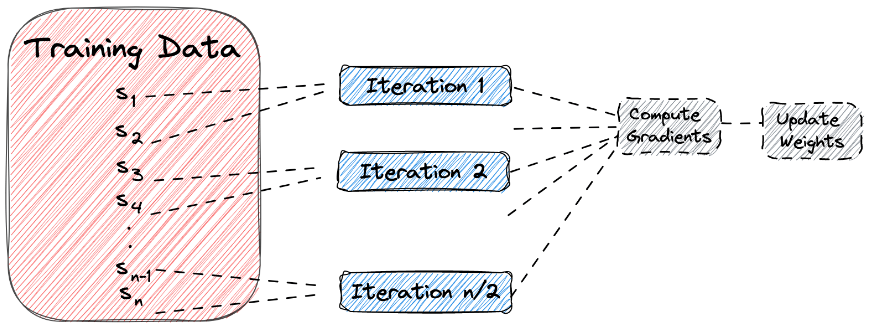
배치단위로 학습을 시키는 것의 장점
- 효율적인 데이터 로딩: 대용량의 데이터를 처리할 때 효율적으로 메모리에 로드하고 관리할 수 있습니다.
- 병렬 처리: 데이터로더는 병렬 처리를 지원하여 훈련 과정에서 데이터 로딩과 모델 훈련을 동시에 수행할 수 있습니다. 이는 전체 훈련 시간을 단축시키는 데 도움이 됩니다.
- 미니배치 처리: 데이터를 미니배치로 나누어 제공하여 효율적인 학습을 가능하게 합니다. 이는 모델이 전체 데이터셋을 한 번에 처리하는 것보다 더 안정적인 학습을 가능케 합니다.
- 자동 데이터 셔플링: 데이터로더는 데이터를 자동으로 셔플하여 모델의 편향을 방지하고 학습의 다양성을 높일 수 있습니다.
배치단위로 학습을 시키는 것의 단점
- 추가 오버헤드: 데이터를 로드하고 전처리하는 과정에서 일부 오버헤드가 발생할 수 있습니다. 이는 작은 규모의 데이터셋에서는 미미하지만 매우 큰 데이터셋의 경우에는 고려해야 할 요소가 될 수 있습니다.
- 메모리 사용량: 대규모 데이터셋을 처리할 때 메모리 사용량이 증가할 수 있으며, 이는 메모리 제한이 있는 환경에서 문제가 될 수 있습니다.
- 성능 영향: 잘못된 구성 또는 사용 방법으로 인해 데이터로더가 성능에 영향을 미칠 수 있습니다. 따라서 올바른 설정과 사용법을 익히는 것이 중요합니다.
학습코드
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
# gpu 사용
device ='cuda' if torch.cuda.is_available() else 'cpu'
print(device)
# 데이터 로드
digits = load_digits()
x_data = digits['data']
y_data = digits['target']
print(x_data.shape) # (1797, 64) -> 1797개의 이미지가 8*8픽셀 사이즈로 존재
print(y_data.shape) # (1797,) -> 얘는 분류값이라 1797개의 라벨값
# 이미지 시각화 및 라벨값 동시 출력
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(14,8))
for i, ax in enumerate(axes.flatten()):
ax.imshow(x_data[i].reshape((8,8)), cmap='gray')
ax.set_title(y_data[i])
ax.axis('off')
학습을 위해 x_data는 float형으로 y_data는 long형으로 변환
float는 실수이고 long은 정수형인데요.
실제로 입력되는 값은 float로 소수점을 살려야하고 예측되는 값은 라벨임으로 소수점이 없는 정수로 딱딱 나눠 떨어져야 함으로 변환해주는 것입니다.
만약 y를 long이 아니라 float형으로 변환해준다면 오류가 날 수도 있습니다.
x_data = torch.FloatTensor(x_data)
y_data = torch.LongTensor(y_data)
print(x_data.shape)
print(y_data.shape)
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=2024)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# drop_last = False로 하면 64의 배수가 안되서 버려지는 애들이 안버려지고 마지막 배치 사이즈는 64개가 아닌 상태로 돎
# 버려지는 애들은 없지만 남은 애들끼리 모여서 수가 적음
# torch.utils.data.DataLoader안에 들어가는 dataset은 list여야함으로 zip 사용하여 묶어줌
loader = torch.utils.data.DataLoader(
dataset = list(zip(x_train, y_train)),
batch_size = 64,
shuffle = True
)
#loader 잘 만들어졌는지 확인
# iter 하나씩 next 차례대로
imgs, labels = next(iter(loader))
# next를 한번 해줬기때문에 64개가 나옴 (배치 사이즈)
# 돌릴때마다 달라짐
labels
#loader 잘 만들어졌는지 확인22
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14,14))
for ax, img, label in zip(axes.flatten(),imgs, labels):
ax.imshow(img.reshape((8,8)),cmap='gray')
ax.set_title(str(label))
ax.axis('off')
모델 설정
오늘은 아주 간단하게 한 레이어만 있는 애를 만들어 보겠습니다.
digits 데이터셋은 아주 좋은 데이터셋임으로 이런 허접한 레이어를 가진 모델에서도 잘 작동합니다.
model = nn.Sequential(
nn.Linear(64, 10)
)
optimizer = optim.Adam(model.parameters(), lr=0.01)
epochs = 50
for epoch in range(epochs + 1):
sum_losses = 0
sum_accs = 0
# 전체 데이터에서 64만큼 뽑아서 학습시키는걸 전체 데이터를 다 64개씩 뽑고 64개 이하는 버리는게 한번 epoch!
# 배치사이즈가 64면 64개마다 기울기를 업데이트하는 것
# 기울기 업데이트 시점이 중요
# 기울기를 자주 업데이트하면 속도가 빨라짐(정답을 빨리 찾을수있음)
# loader는 이전에 설정할때 정해져있고 epoch 돌면서 바뀌지 않음
for x_batch, y_batch in loader:
y_pred = model(x_batch)
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc
avg_loss = sum_losses / len(loader)
avg_acc = sum_accs / len(loader)
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%')
plt.imshow(x_test[10].reshape(8,8),cmap='gray')
print(y_test[10])
y_pred = model(x_test)
y_pred[10]
y_prob = nn.Softmax(1)(y_pred)
y_prob[10]
# tensor([3.2887e-09, 1.8692e-07, 1.5112e-11, 7.1228e-08, 1.8645e-07, 4.5024e-09,
# 1.7375e-12, 9.9997e-01, 4.8948e-07, 3.2180e-05],
# grad_fn=<SelectBackward0>)
for i in range(10):
print(f'숫자 {i}일 확률: {y_prob[10][i]:.2f}')
# 숫자 0일 확률: 0.00
# 숫자 1일 확률: 0.00
# 숫자 2일 확률: 0.00
# 숫자 3일 확률: 0.00
# 숫자 4일 확률: 0.00
# 숫자 5일 확률: 0.00
# 숫자 6일 확률: 0.00
# 숫자 7일 확률: 1.00
# 숫자 8일 확률: 0.00
# 숫자 9일 확률: 0.00
y_pred_index = torch.argmax(y_prob, axis=1)
accuracy = (y_test == y_pred_index).float().sum() / len(y_test) * 100
print(f'테스트 정확도는 {accuracy :.2f}입니다')
# 테스트 정확도는 95.83입니다여기서 아주 간단하게 정리를 하자면 순서는 이렇습니다.
1. 데이터로드
2. 데이터로더로 배치쌍으로 묶기
3. 모델 학습(모델 생성, 배치별로 정확도와 loss값 계산, epoch별로 정확도와 loss값 출력)
4. 학습이 완료된 model에 test데이터 입력
5. Softmax로 라벨별 예측값 계산 -> torch.argmax로 가장 높은 확률인 라벨 출력
6. 가장 높은 확률인 라벨의 값과 실제 y값을 매치해서 정확도 평가
오늘은 그저 데이터 로더를 이해하고 활용하는 법을 알아보기 위한 글이였고 다음 글엔 모델을 cnn을 사용해서 제대로된 딥러닝 학습을 해보겠습니다.